Offline Azure SQL managed instances on-prem
Tovább gyűrűzik a hybrid szolgáltatások köre és úgy néz ki, hogy nem akar elfogyni a Microsoft-nál sem a különböző Azure szolgáltatások földi környezetbe való átültetése. Jó egy évvel ezelőtt írtam az Azure Arc SQL Managed Instance how-t. Maguk a lépések egyszerűek voltak. Kell egy földi kubernetes, onboarding-olni Azure ARC-al, létrehozni Data controller-t és custom location-t és már el is készültek az Azure management SQL szolgáltatásaink. Ekkor létrehozhattunk egy Azure által managelt SQL cluster-t úgy, hogy a metrika, a log-ok direktben felkerültek a kijelölt előfizetésünk megfelelő részeibe. Innen következik, hogy ez egy állandó internet kapcsolatot igényelt, mivel minden management a portálon is elérhető volt, vagyis a földön volt minden, de a felhő kapcsolatot azért soha nem veszítettük el :)
A mostani felállás is hasonló lesz, annyi kivétellel, hogy nem kell minden log-ot Azure-ba küldenünk. Minden! szolgáltatás a földön lesz elérhető, tehát a terhelési monitorozás vagy a log-ok, mind-mind a földön fognak elhelyezkedni és havonta egyszer elég felküldenünk az úgymond fogyasztási adatokat, ami egy emberi szem számára is “olvasható” json lesz.
Hogyan hozzuk létre…
Előfeltételek
Csupán a K8s cluster bevonása maga nem igényel sok erőforrást, de a későbbiekben a “data controller” és az SQL rezervált processzorral és memóriával fognak elindulni, hiába nem terhelik üresen a gépeket.
Így Én azt javaslom, hogy minimum a következő paraméterekkel rendelkezzen a VM:
- 10 vCpu
- 20GB Mem
- 100GB disk
Ezen kívül persze
- Jogosultság előfizetésben (owner)
- AzureAD-ban Service Principal létrehozáshoz való jog
- Azure előfizetés amibe van pár $
- Rendszergazdai jog
Kubernetes
Az újrahasznosítás jegyében a microk8s létrehozását már egy előző postban leírtam itt,de ismétlés a tudás…
Alap Ubuntu telepítésén sokat nem szeretnék magyarázni, de pár képben azért megmutatom az alapbeállításokat.
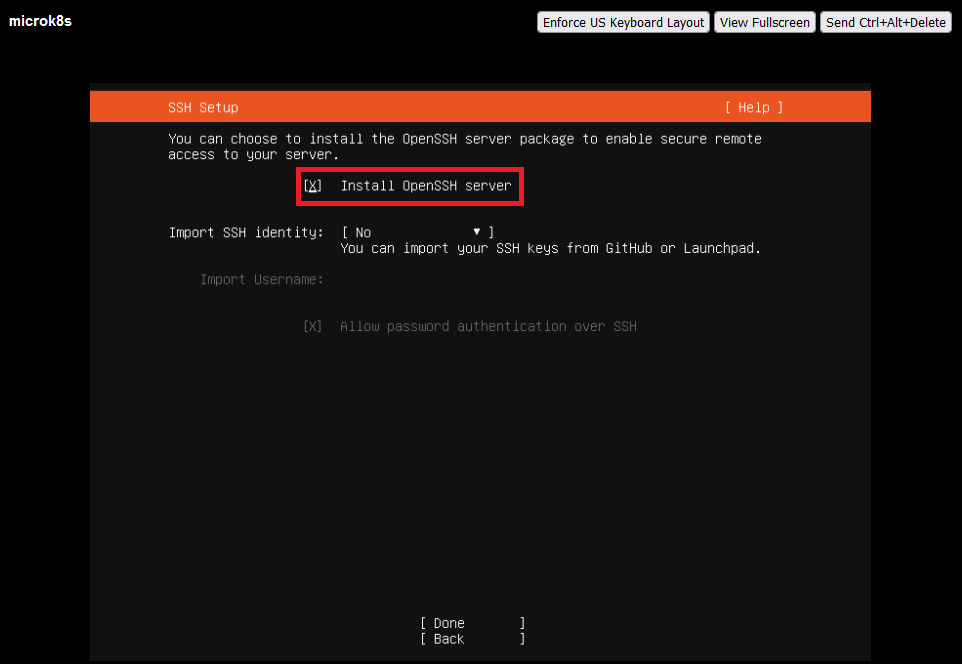
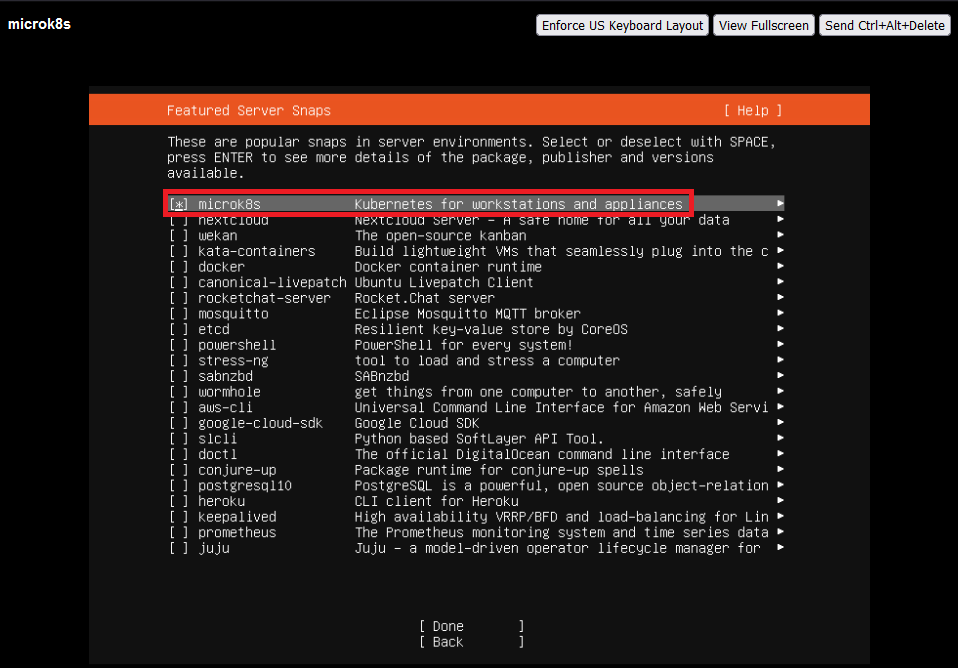
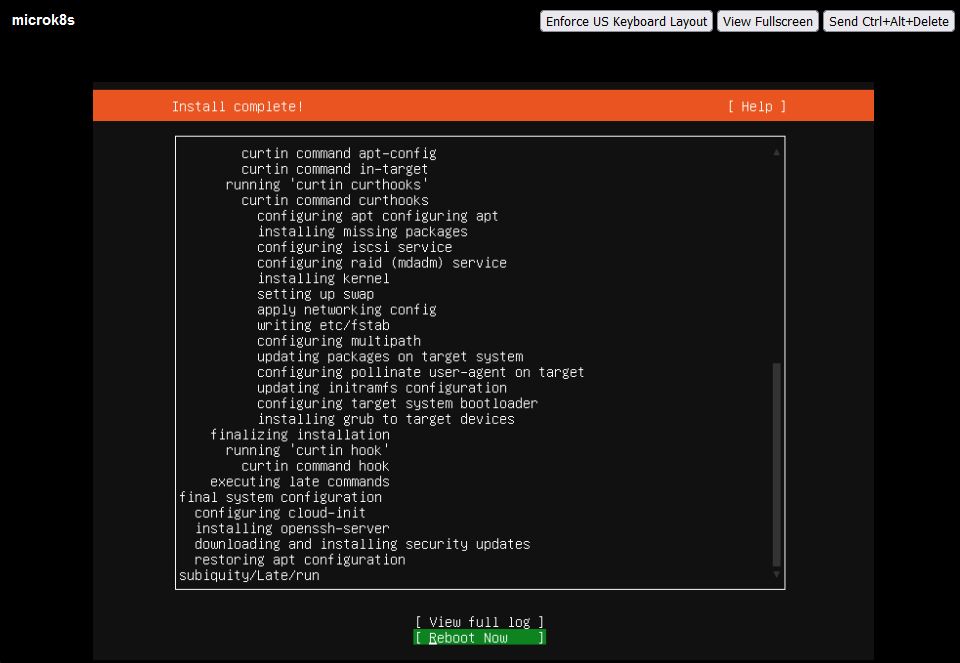
Persze kézzel utólag is telepíthetjük ;)
1
sudo snap install microk8s --classic
Végül a microk8s-es szolgáltatásokat kapcsoljuk be, hogy készen álljon a telepítésre a környezet, így csatlakozzunk SSH-n és futtassuk le a következőt root-ként:
1
microk8s enable dns storage helm registry dashboard
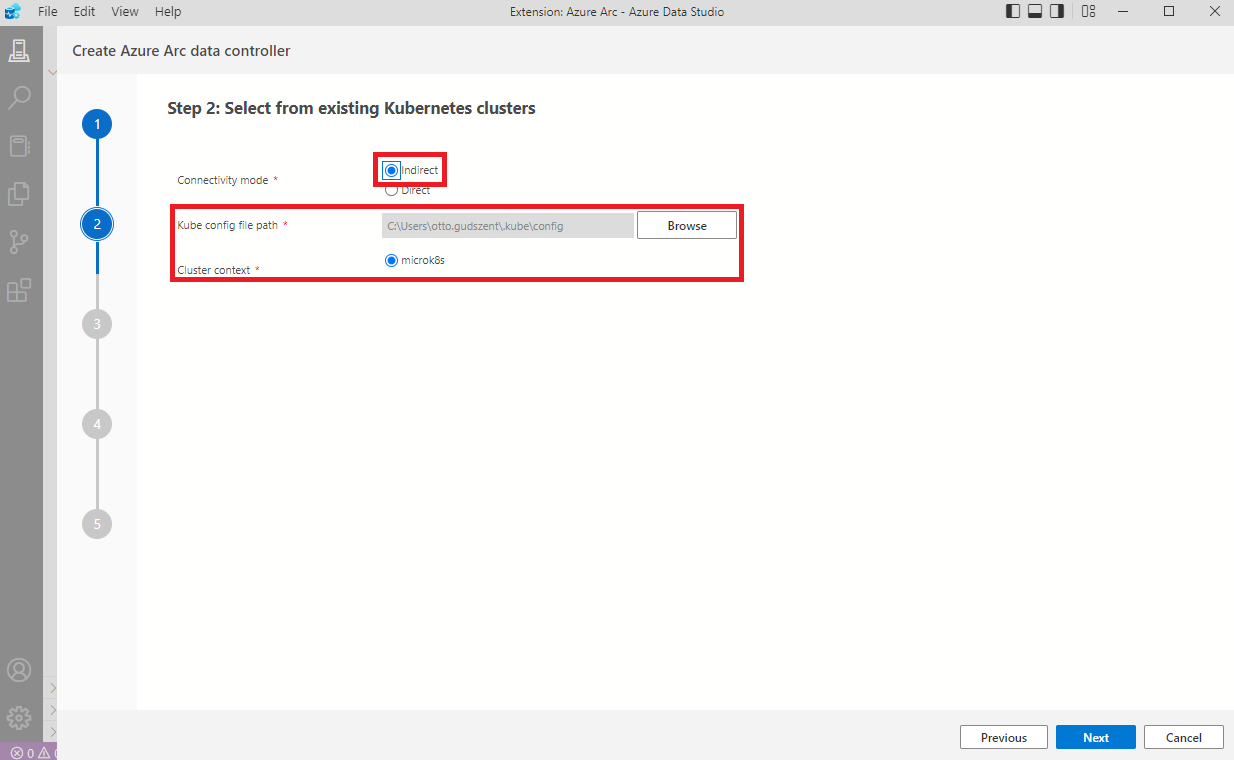
Direct vs Indirect Data Controller
Két féle Azure Arc data controller van, Direct és Indirect.
- Direct esetében online a kapcsolat, Azure-ba feltöltjük a log-okat stb.
- Indirect módban minden adat a földön marad, kizárólag a számlázással kapcsolatos adatokat kell feltölteni, de ezt a feltöltést megtehetjük másik gépről is, nem feltétlenül kell a szerverről.
Korán lelövöm azzal a poént, hogy nem lehet a portálról létrehozni, hiszen ezt arra hozták létre, hogy Azure mentes környezetben valósuljon meg. Ettől függetlenül a portálon itt található.
Nyissuk meg a https://portal.azure.com -ot -> fenti keresőben írjuk be hogy “Azure Arc” majd:
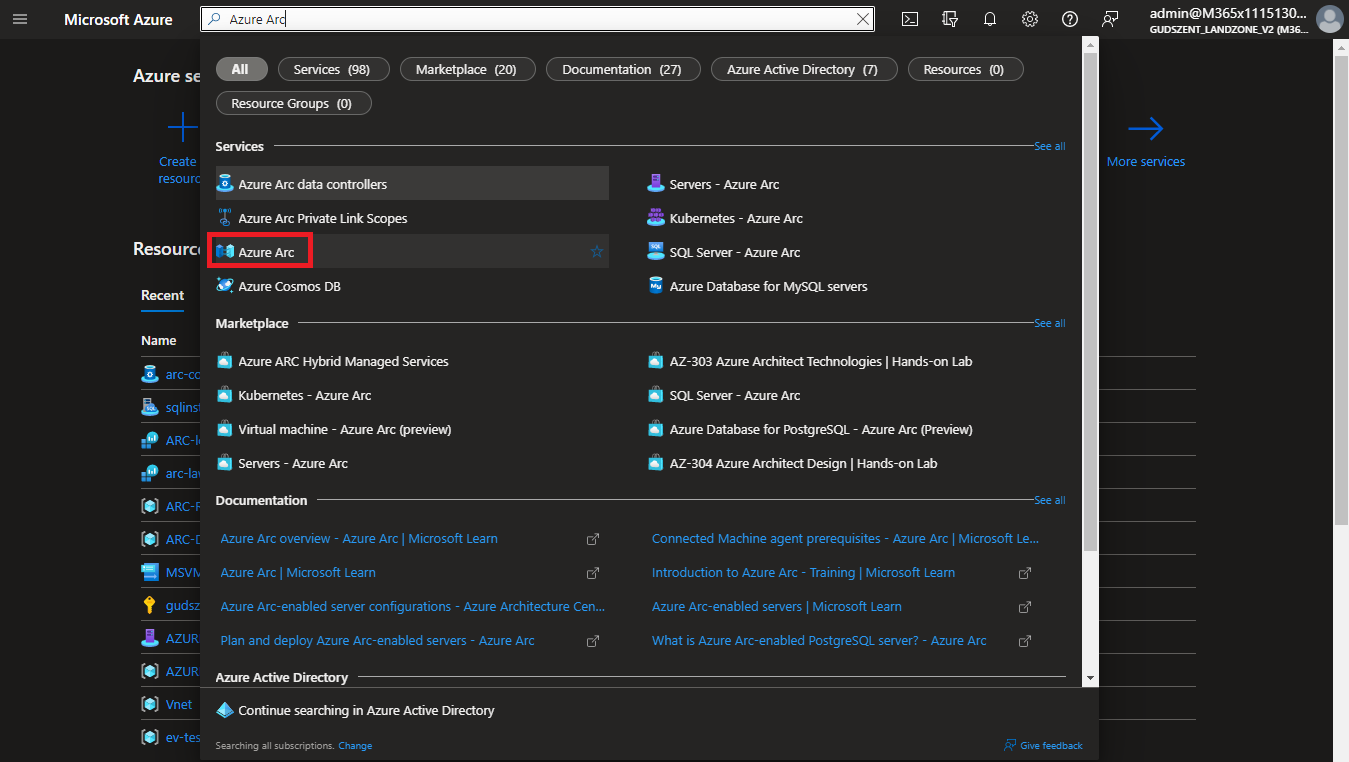
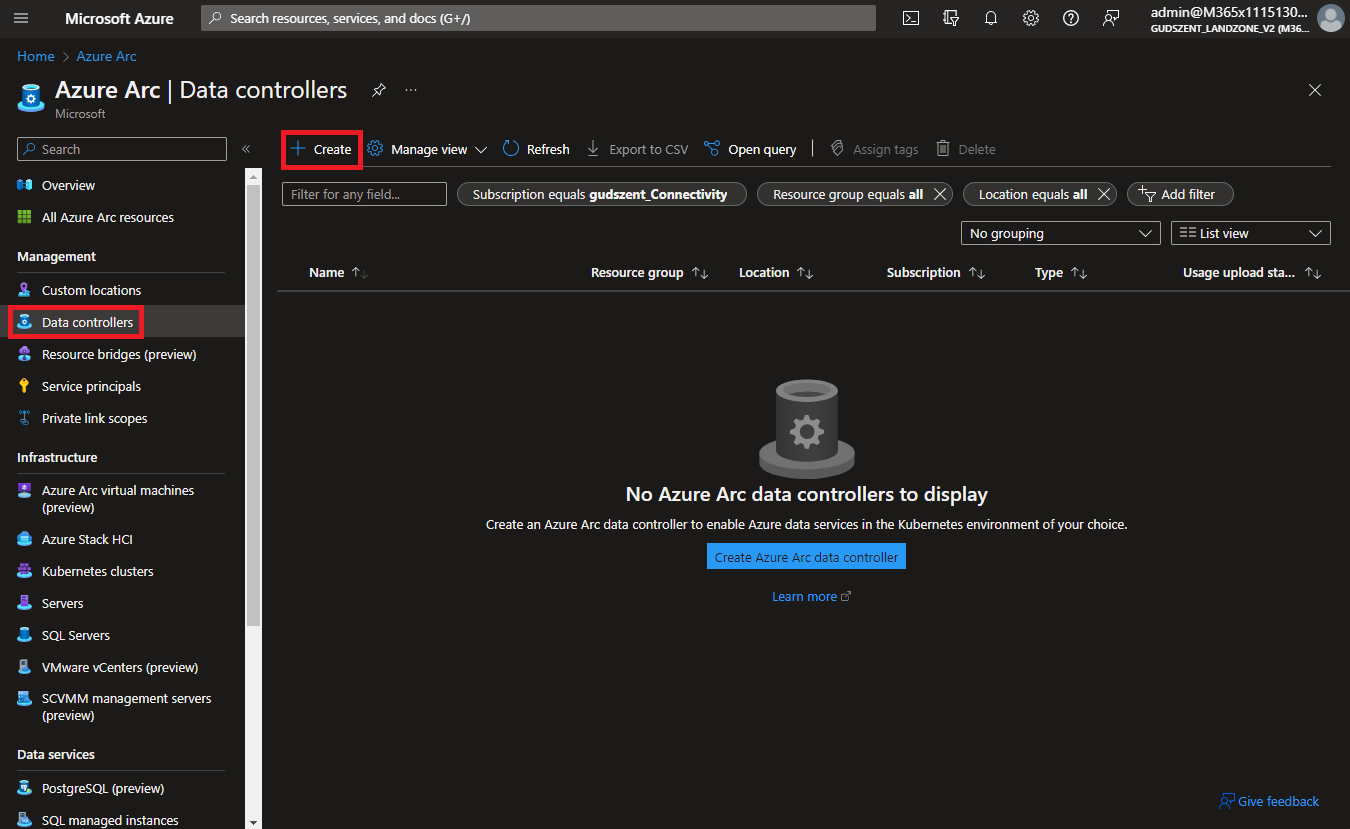
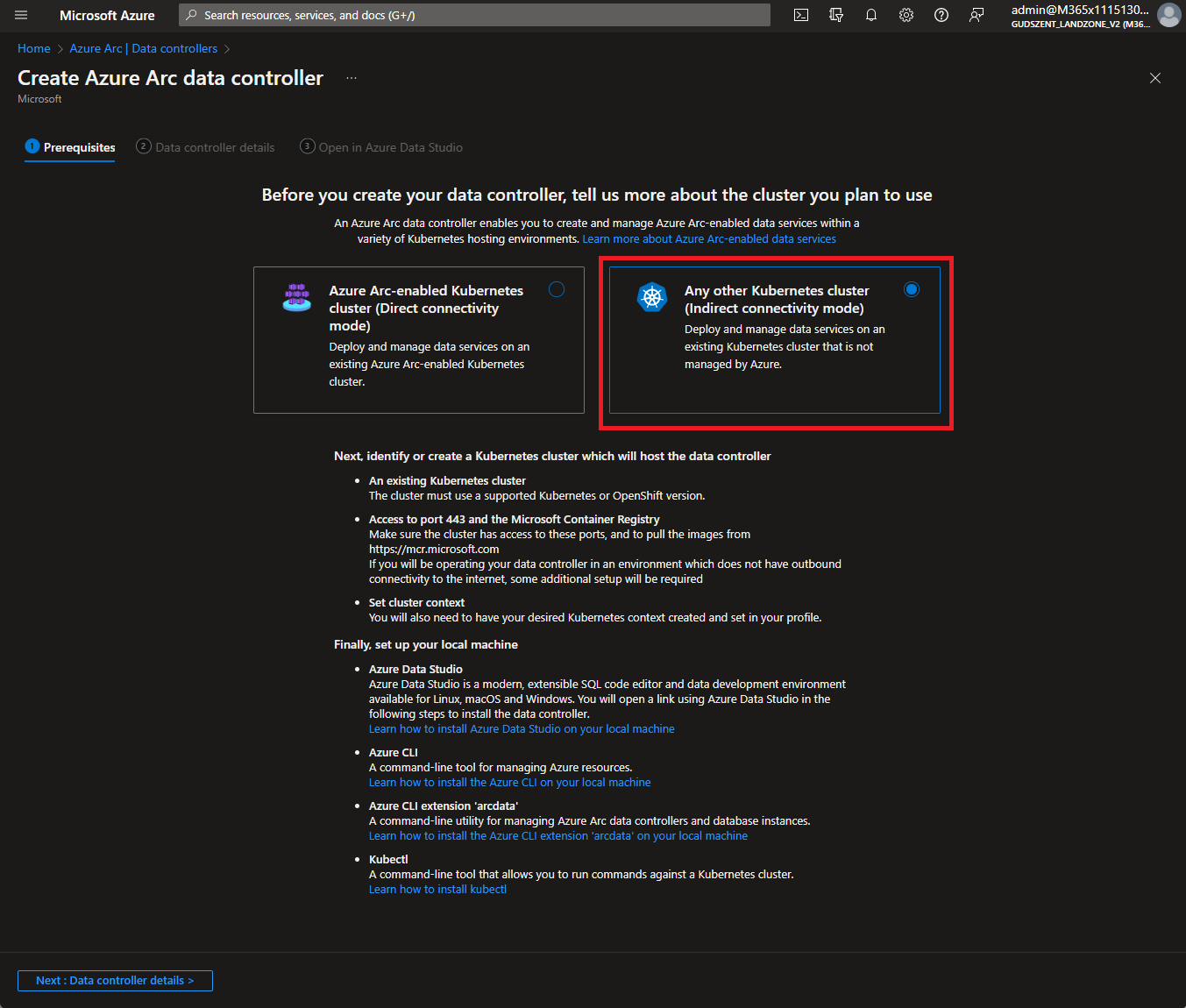
Fel is hívja a figyelmet, hogy két komponens szükséges, hogy feltelepítsünk a gépünkre. 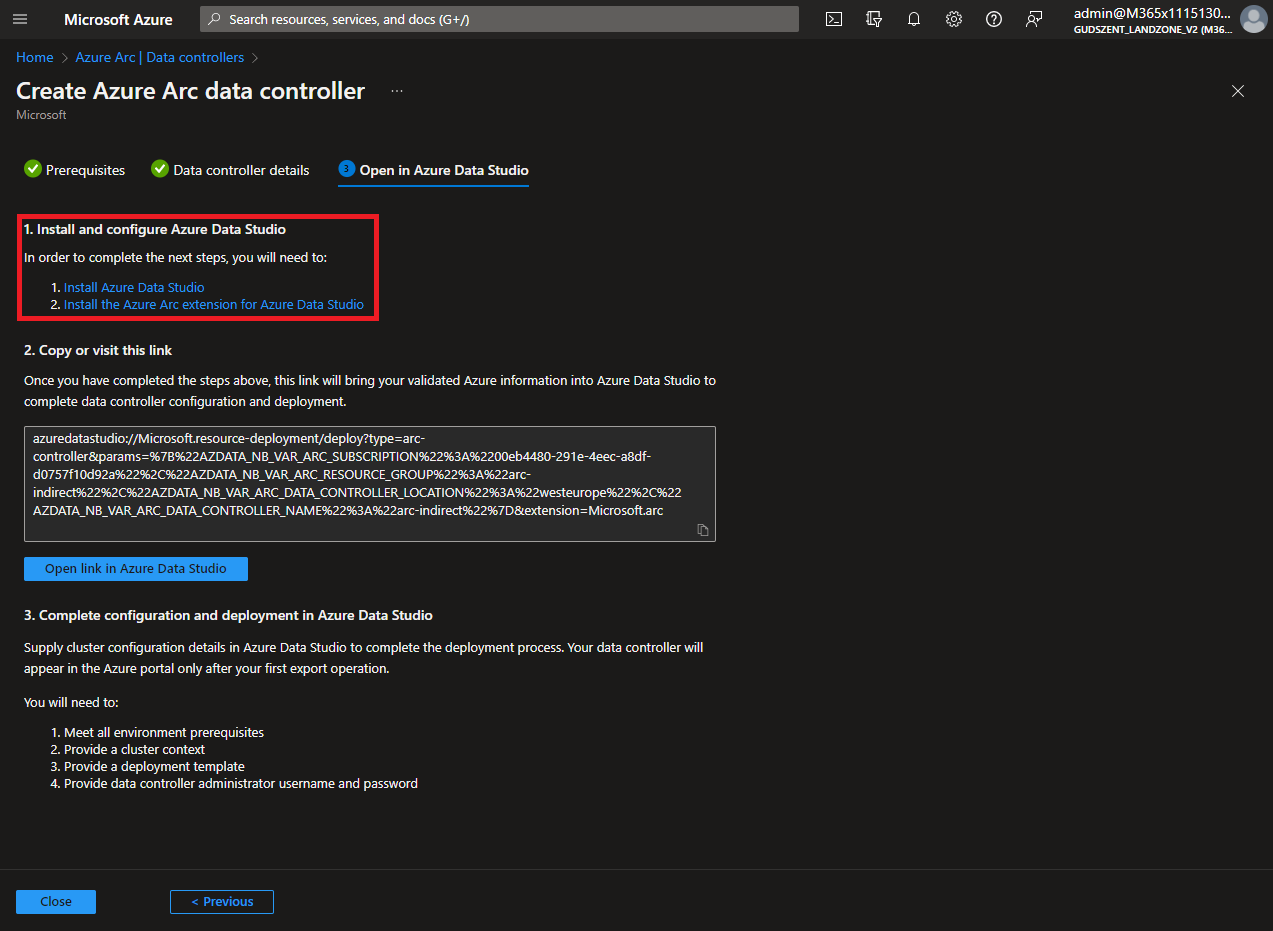
Előfeltételek telepítése
Telepítenünk kell a következő komponenseket:
- Azure Data Studio innen tölthetjük le (User Installer-t ajánlom) és telepítsük.
- Azure CLI innen letölthető, de powershell-ből is telepíthetjük:
1
2
3
$ProgressPreference = 'SilentlyContinue'; Invoke-WebRequest -Uri https://aka.ms/installazurecliwindows -OutFile .\AzureCLI.msi; Start-Process msiexec.exe -Wait -ArgumentList '/I AzureCLI.msi /quiet'; rm .\AzureCLI.msi
- arcdata bővítmény (ha az Azure CLI-t most telepítettük, akkor nyissunk új terminált)
1
az extension add --name arcdata
- kubectl innen letölthető. Javasolt az environment-ek közé felvenni, így később automatikusan felismeri majd a Studio.
Ezután nyissuk meg az Azure Data Studio-t, majd telepítsük fel a kért bővítményt.
Végül, de nem utolsó sorban, be kell szerezni a kube config-ot a feltelepített kubernetes szerverről. Szerencsére könnyen kinyerhető, csak lépjünk be ssh-n keresztül és generáljuk le:
1
2
3
microk8s config >> $HOME/.kube/config
Ezután csak le kell töltenünk a config file-t és helyezzük el.
1
2
3
%USERPROFILE%\.kube
Karakterkódolásra figyeljünk a másolásnál, notepad sajnos elronthatja…
Indirect Data Controller létrehozása
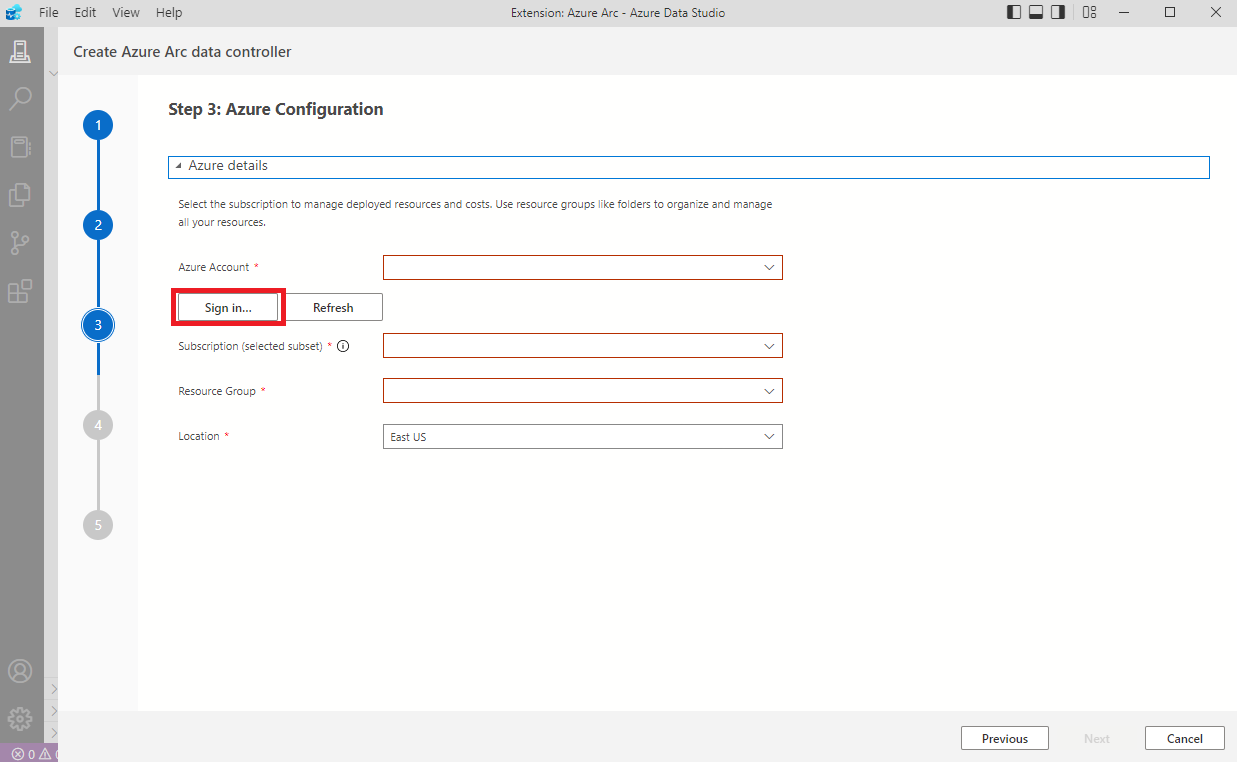
Nyissuk meg a frissen telepített Azure Data Studio-t és kezdjük meg a deployment létrehozását.
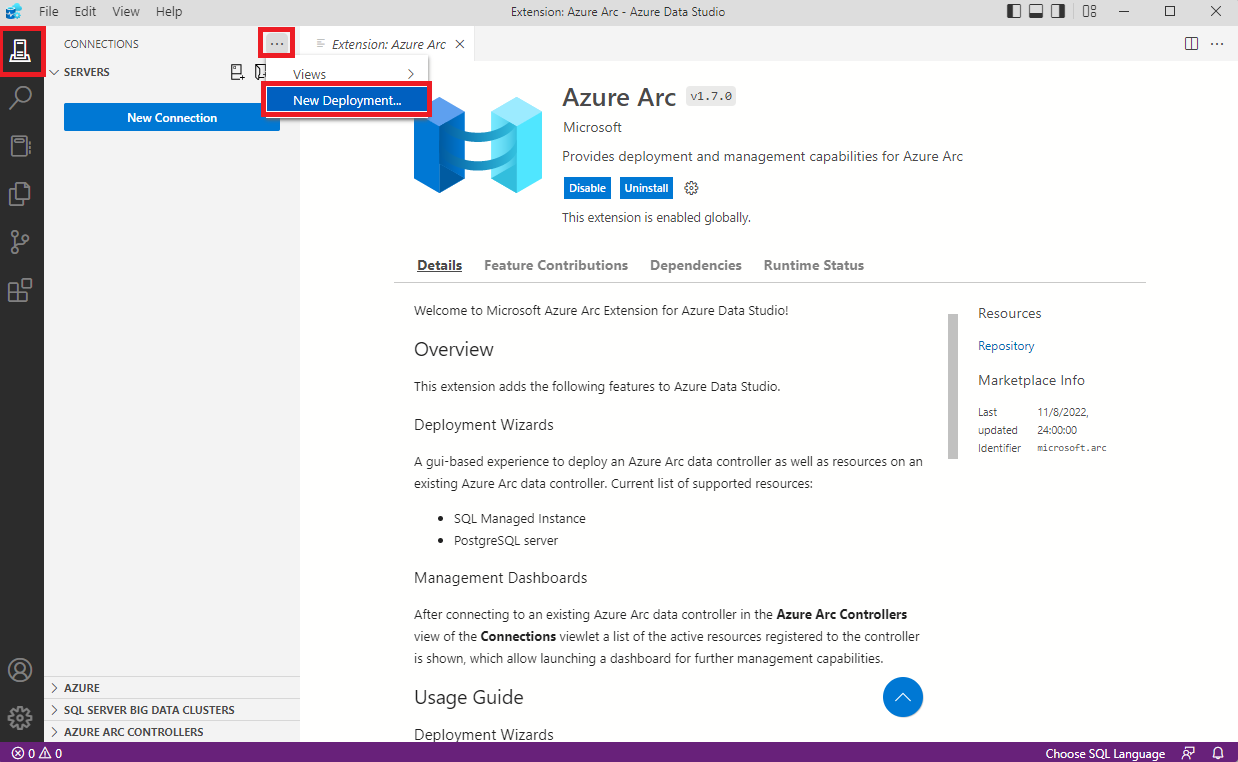
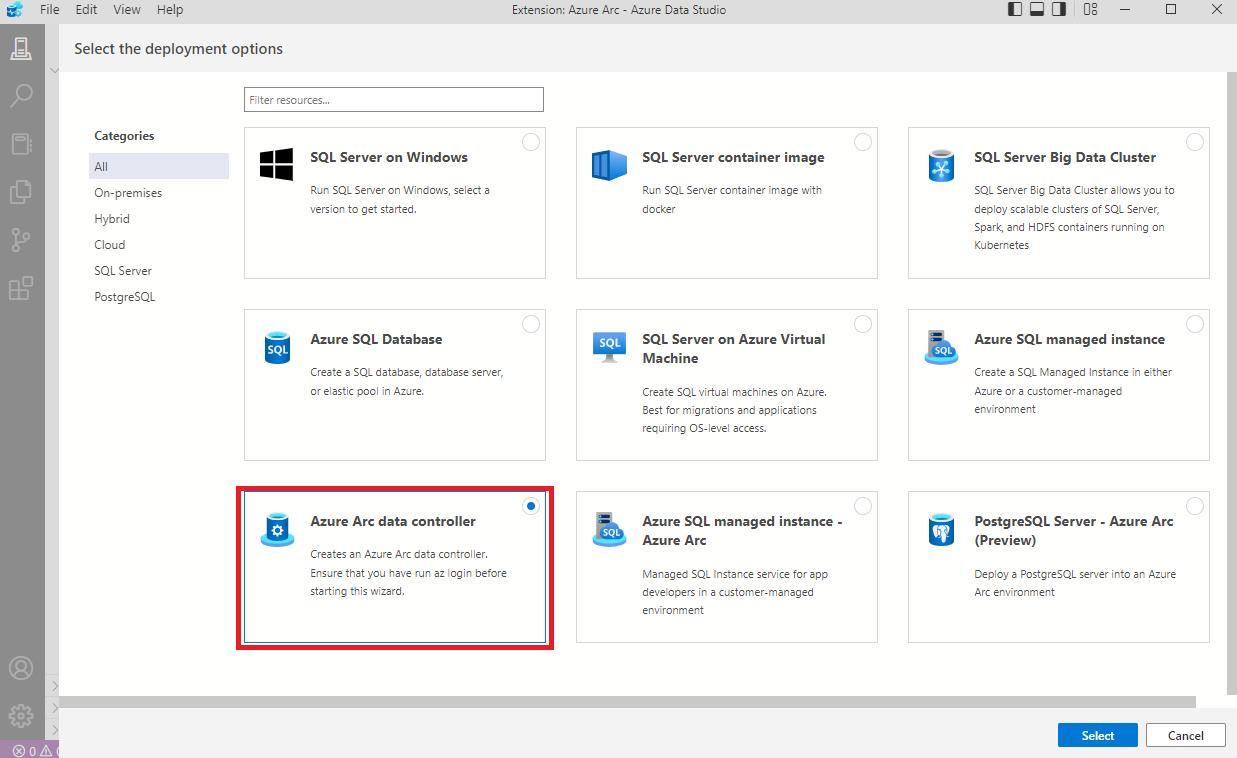
Ha mindent jól telepítettünk fel és állítottunk be, akkor felismer minden szükséges eszközt.
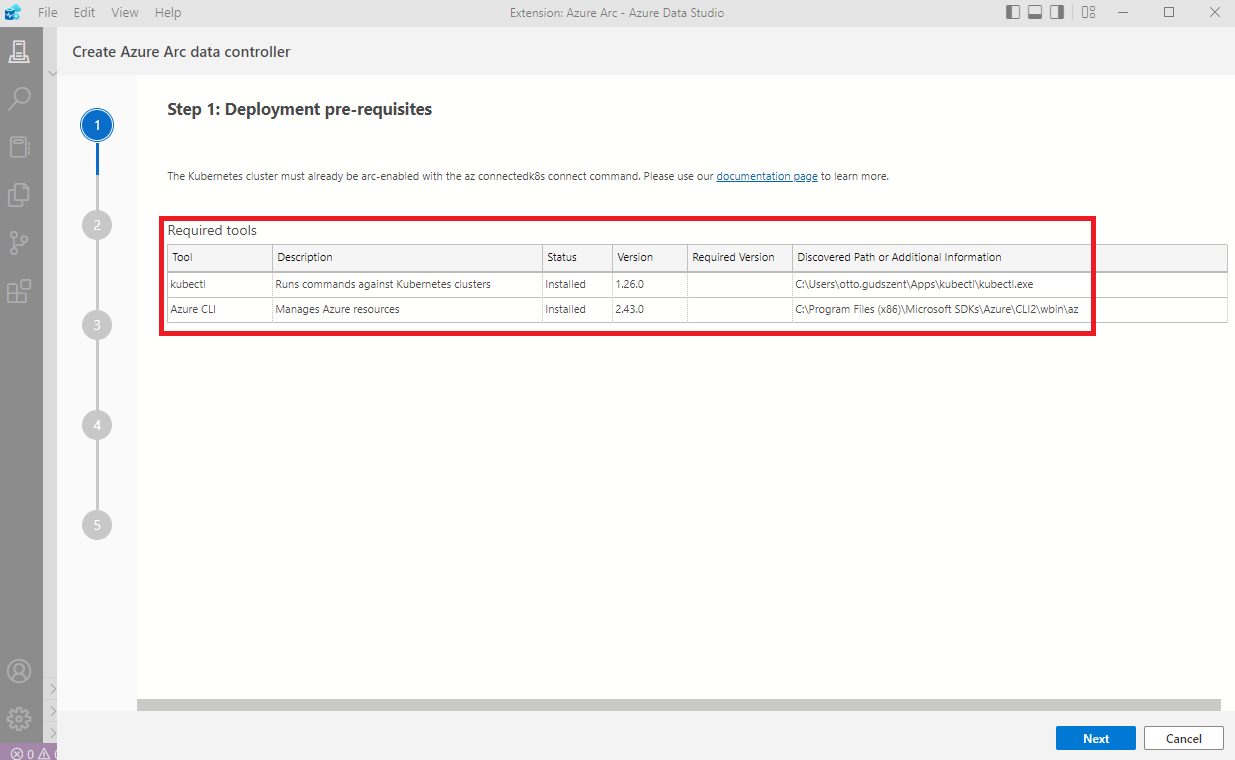
Gyors bejelentkezés
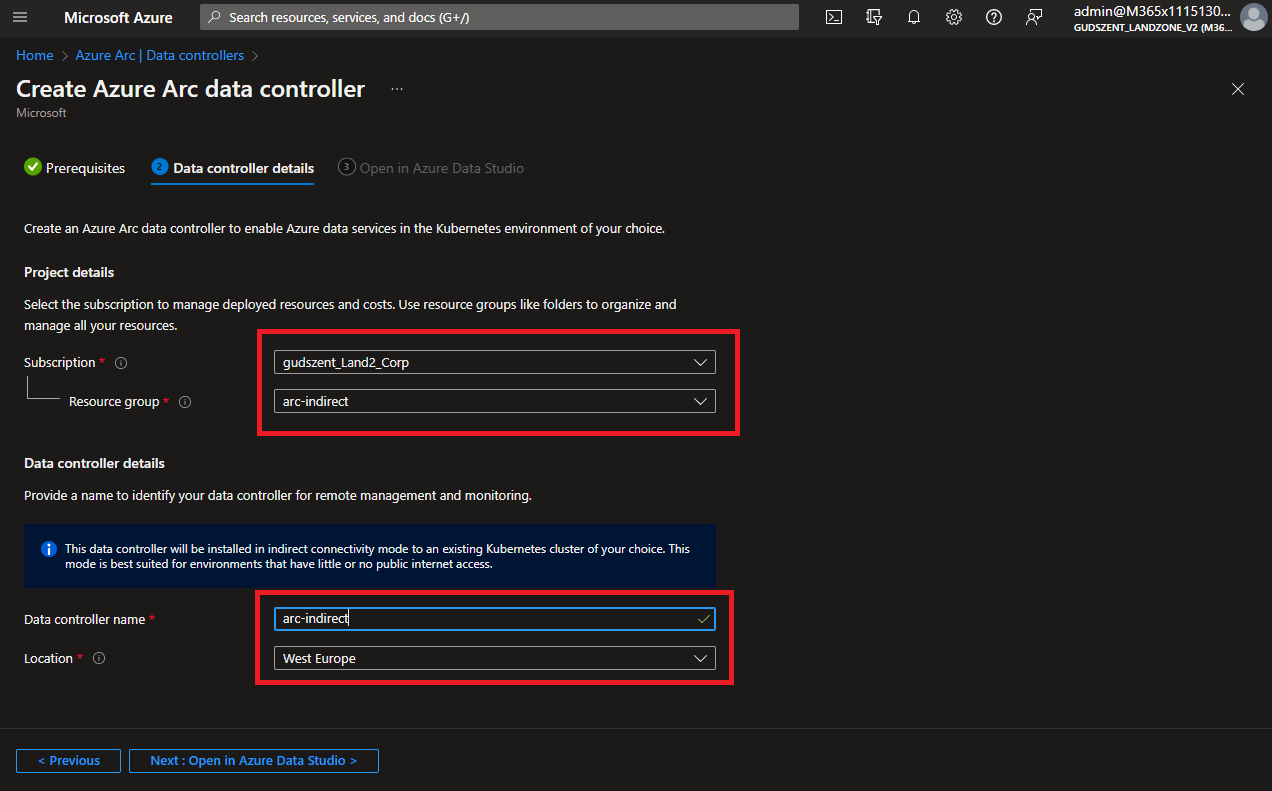
Erről a felületről sajnos nincs lehetőség Resource Group-ot létrehozni, így azt előre a portálon kell.
Válasszuk ki, hol is helyezkedjen majd el a datacontroller-ünk. 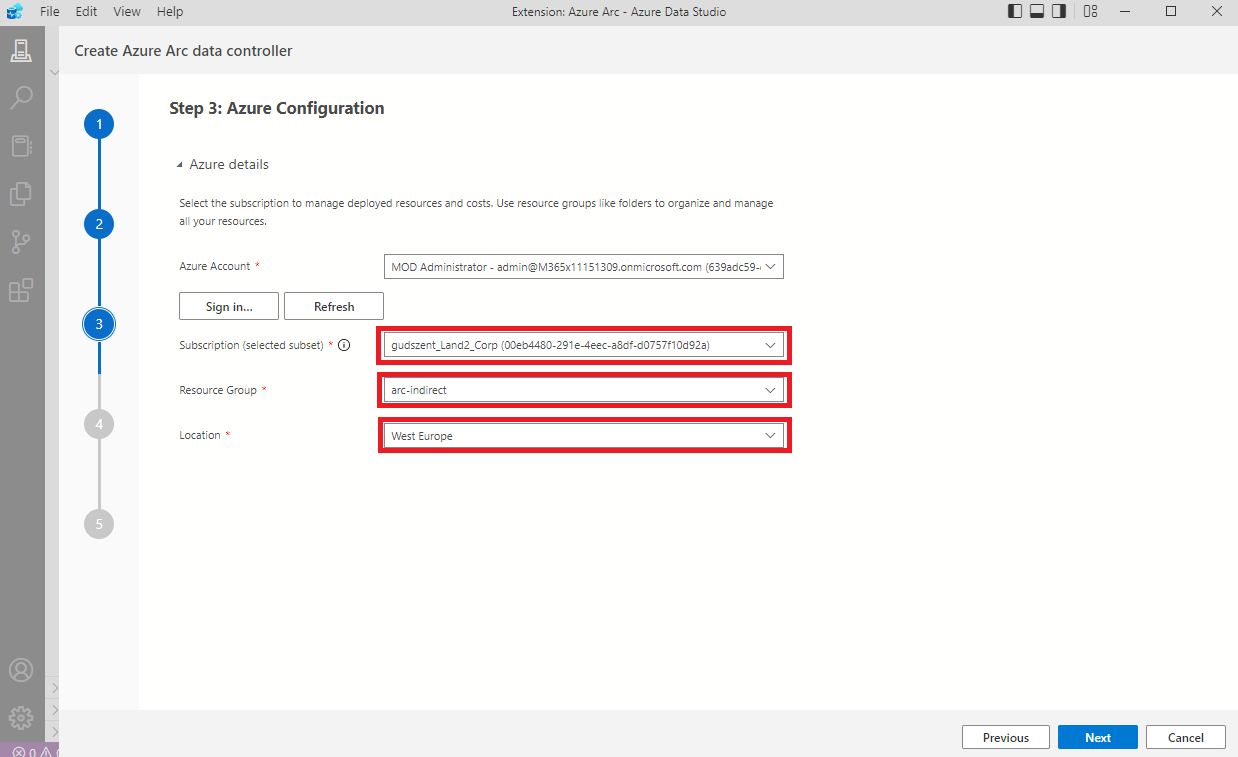
Fontos! “Kubernetes configuration template” és az “Infrastructure” esetében ezeket válasszuk ki, hiszen ezek alapján fogja legenerálni a kubernetes-nek a konfigurációt. Ha rosszat választunk, soha nem fog létrejönni és napokig kereshetjük a hibát. (Egy barátom mesélte..)
Értelemszerűen minden részt ki kell tölteni! 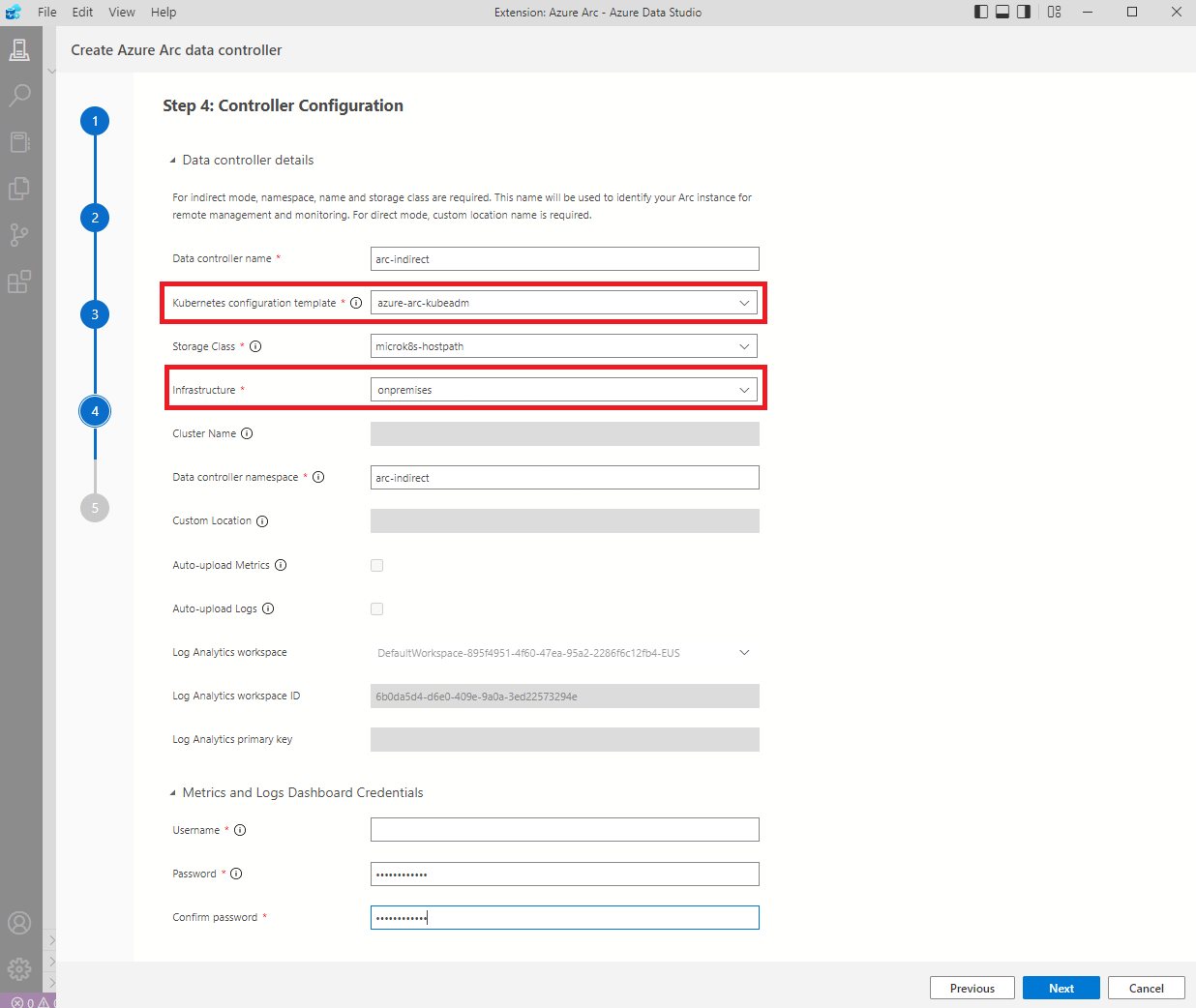
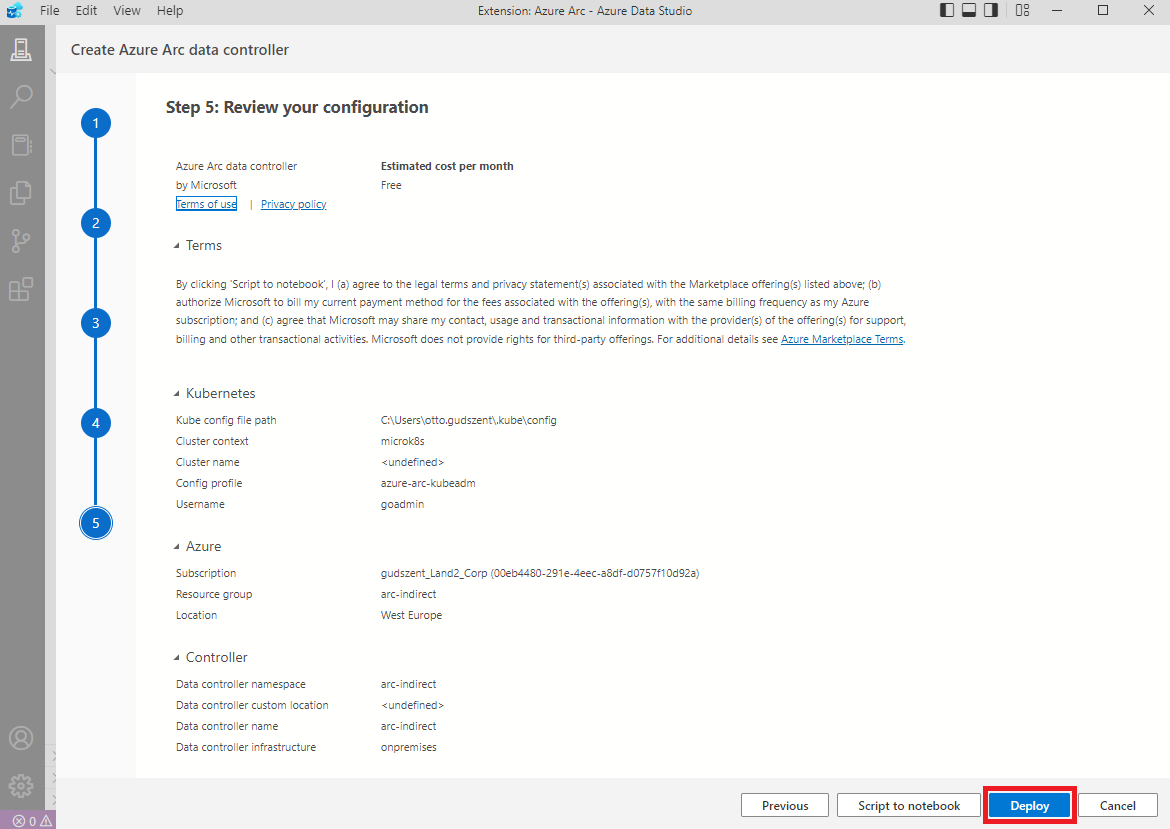
Majd mikor azt hinnénk, hogy elkezdődhet a telepítés, még egy python-t is kell telepíteni. Szerencsére ezt a Studio elkészíti nekünk.
Ha minden jól ment, 5-10 perc múlva a következő üzentet láthatjuk.
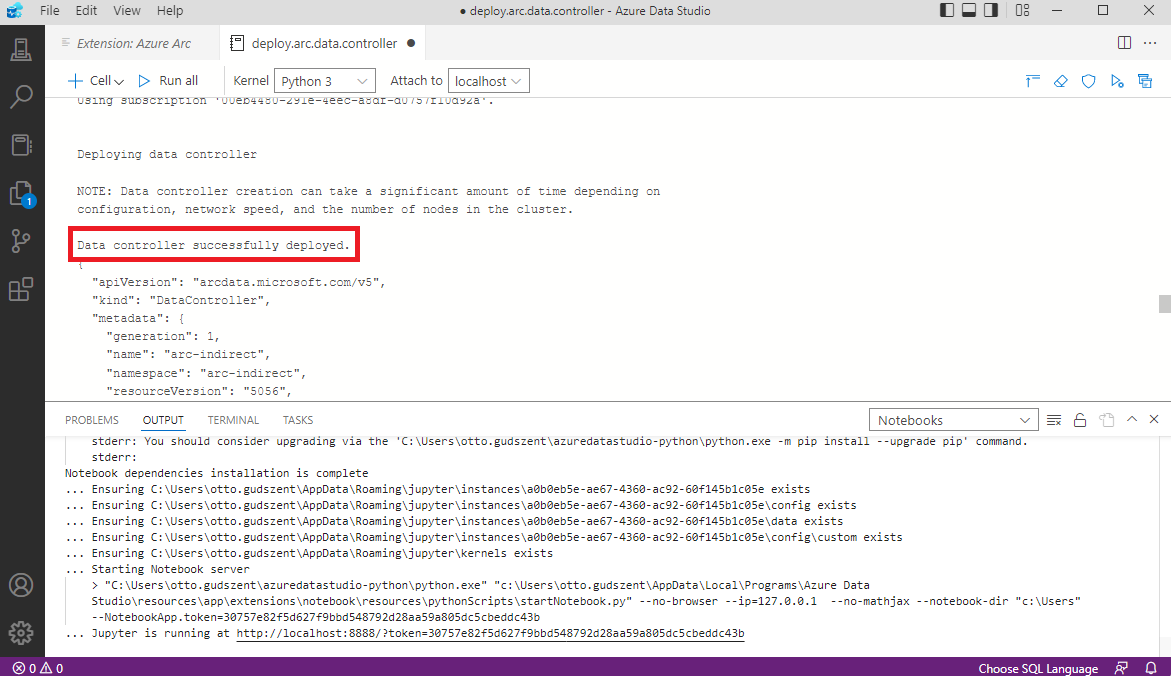
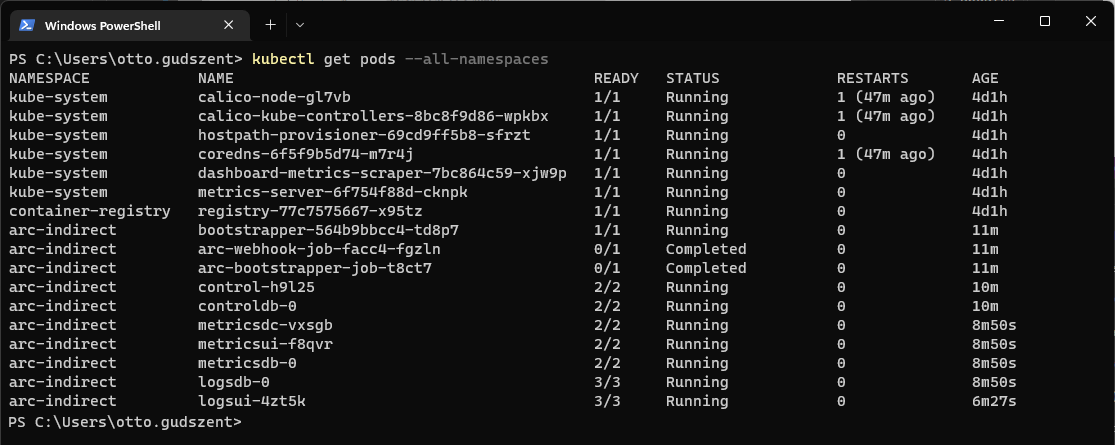
Ha pedig lekérdezzük a kubect-el
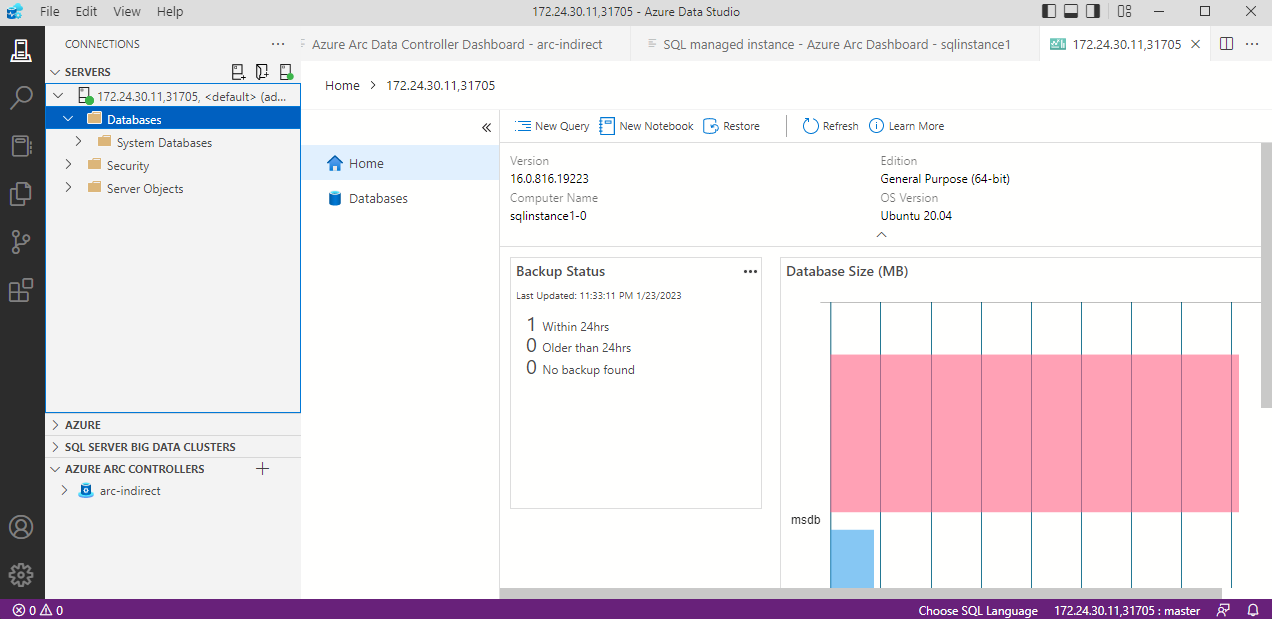
MS SQL létrehozása
Elkészült a Data controller-ünk, most pedig hozzunk létre egy MS SQL instance-ot.
Maradjunk az Azure Data Studio-ban és vegyük fel a frissen elkészült Data controller-t .
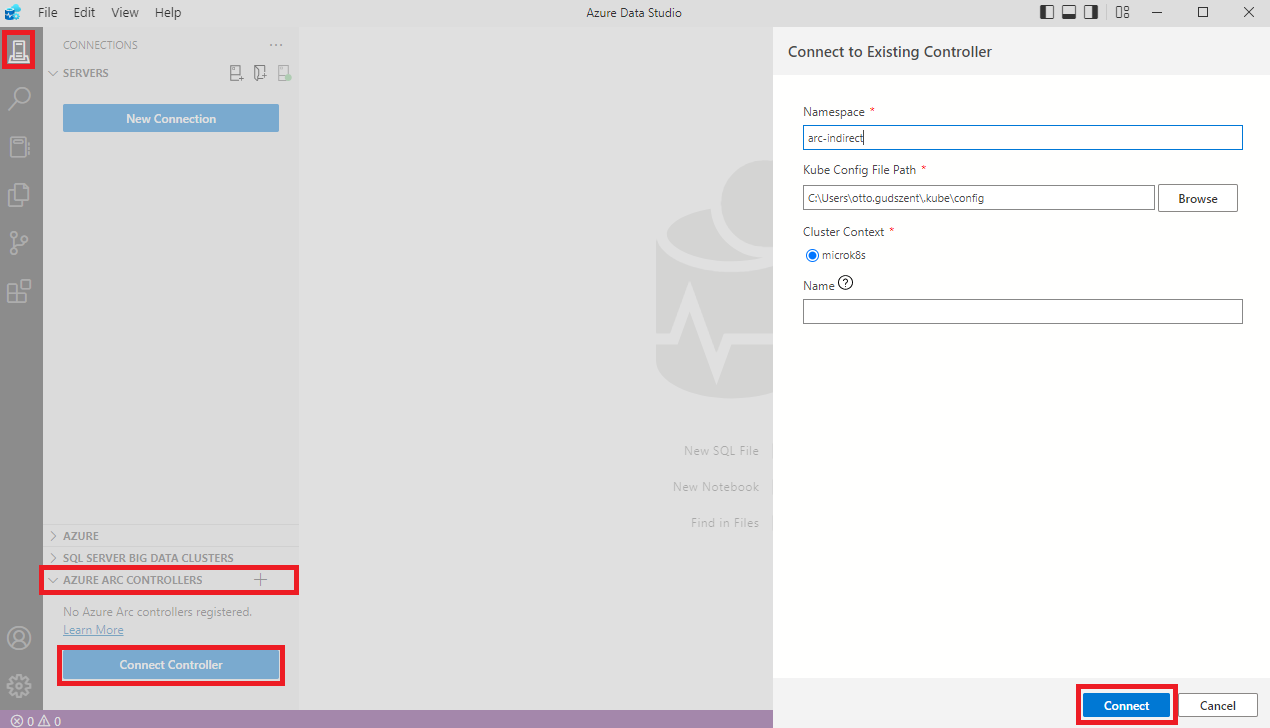
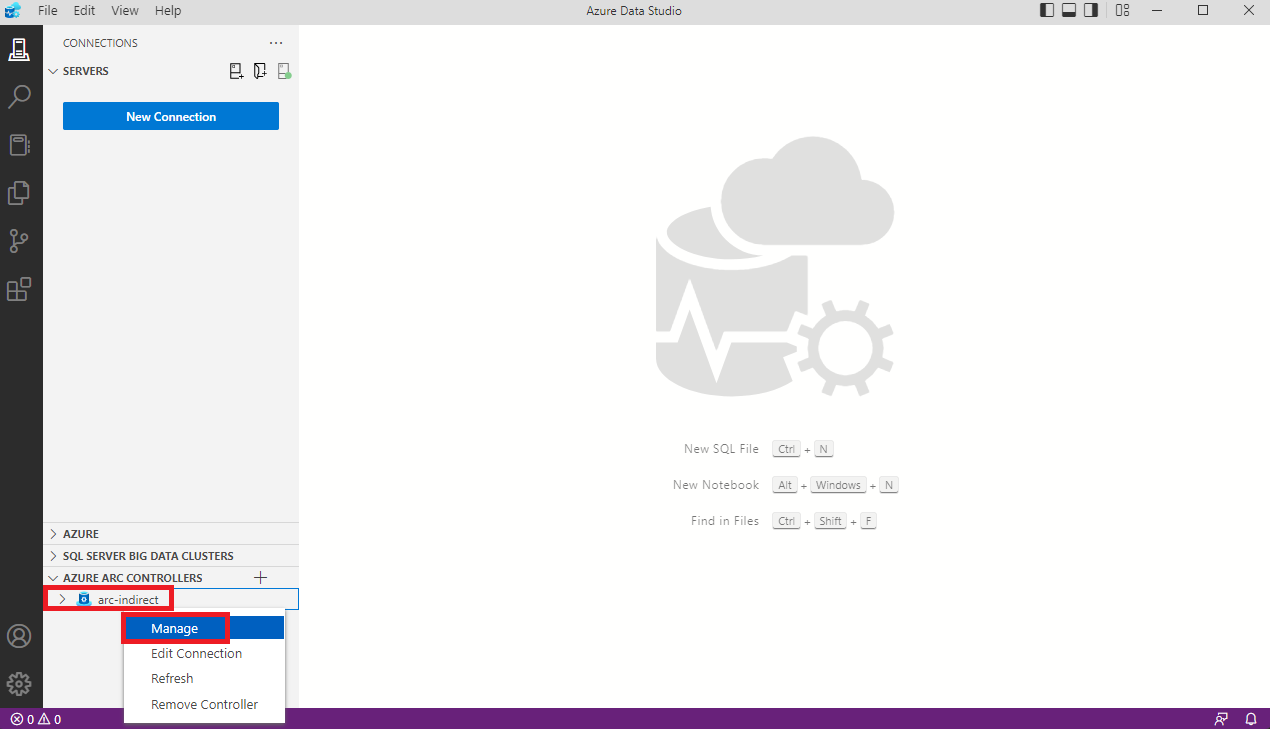
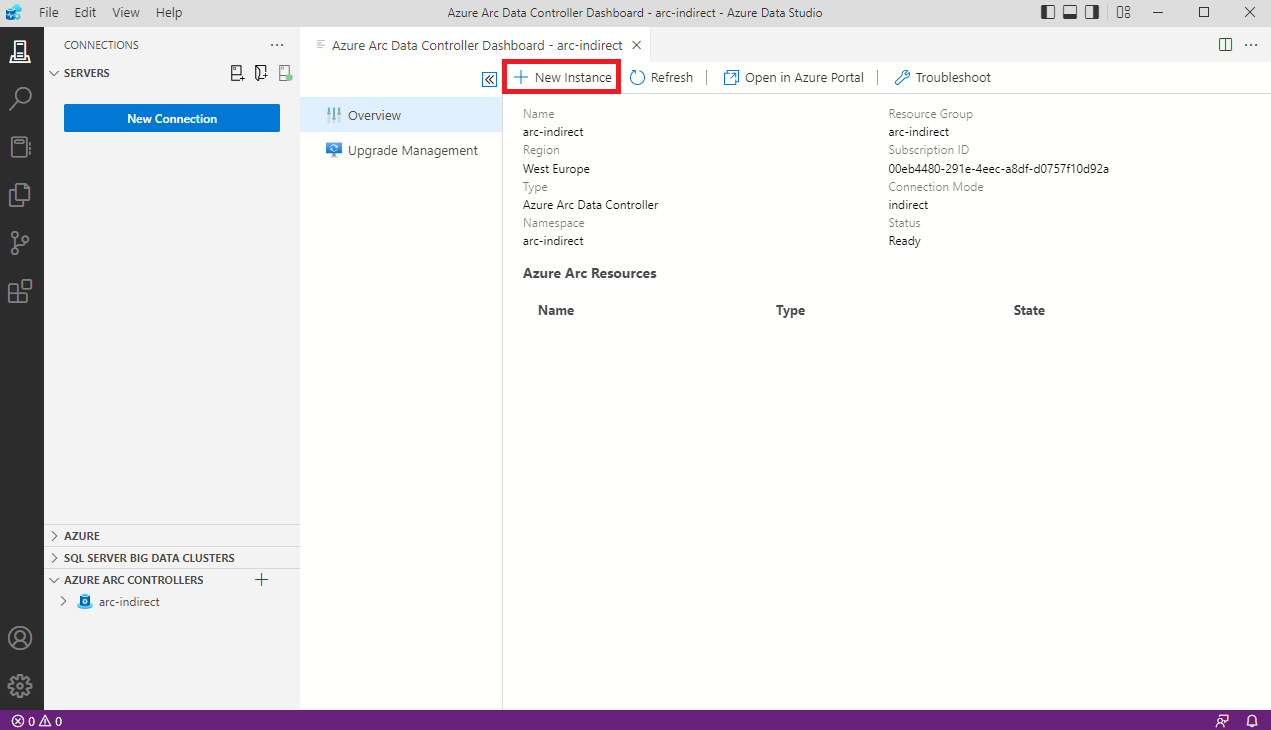
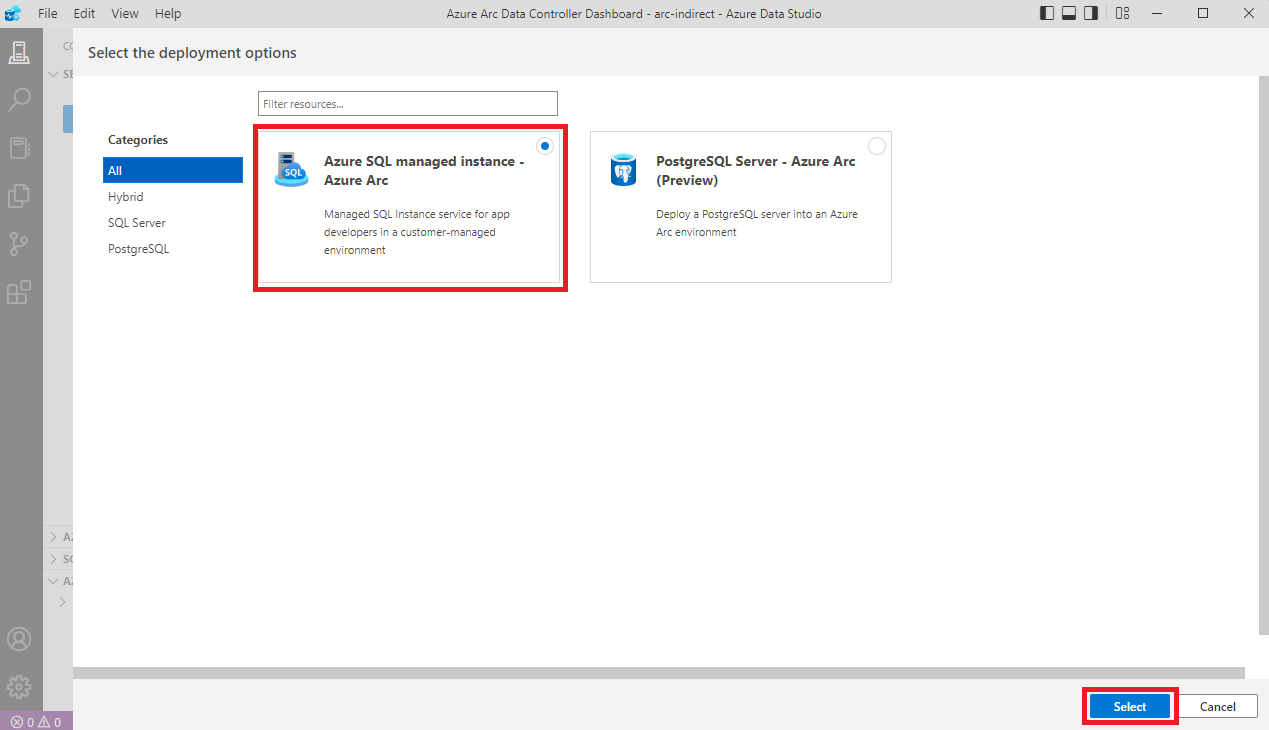
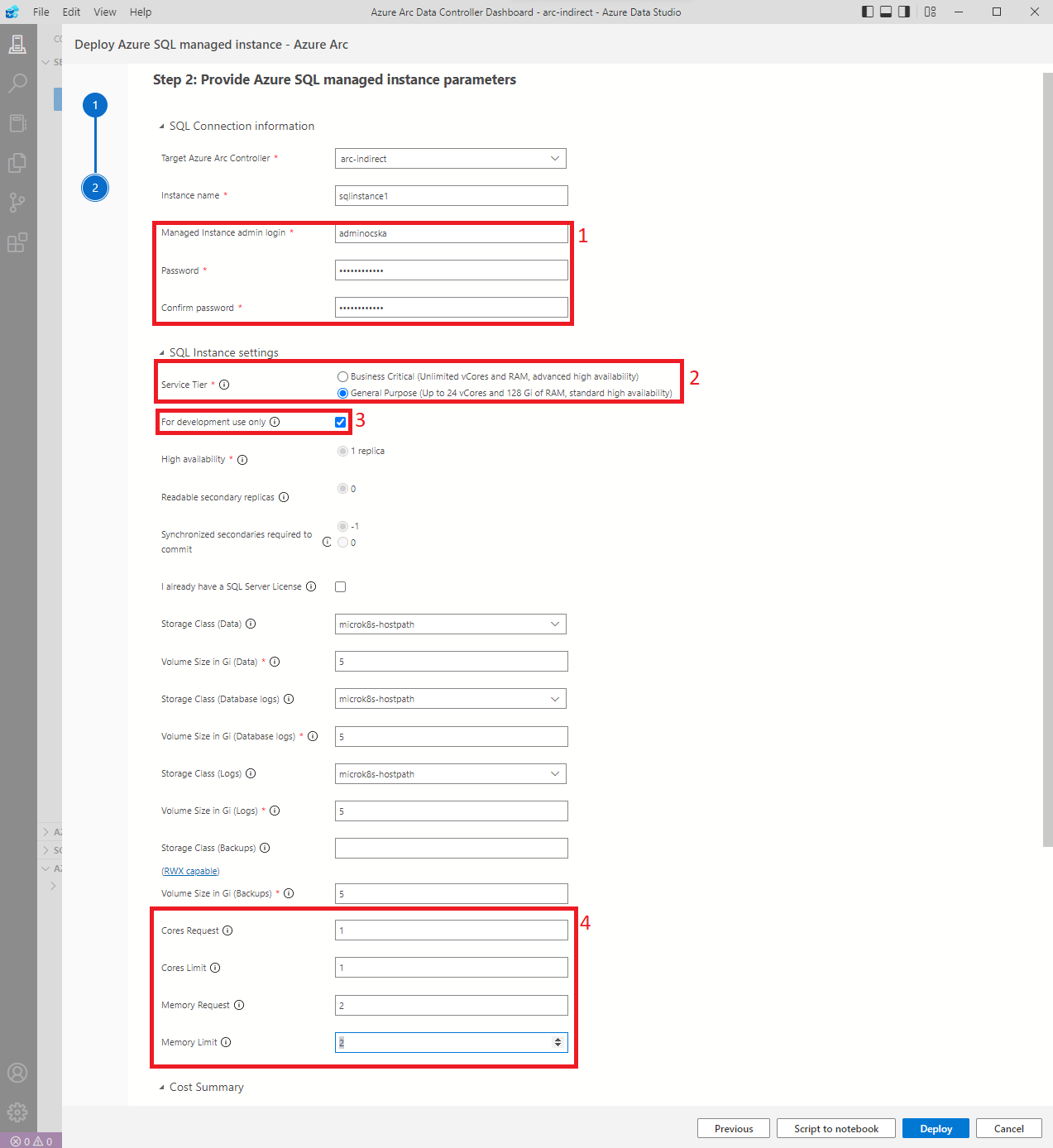
Minden mezőt ki kell tölteni, de kicsit részletezem is a főbb pontokat.
1, Felhasználónév és jelszó, amellyel magára az SQL-re fogunk belépni.
2, Service Tier, magát a felépítését határozza meg, részletesebben itt lehet róla olvasni.
3, SQL licence, soha nem volt egy olcsó dolog, de ha ezt bepipáljuk, úgy vállaljuk, hogy csak Dev/test-re fogjuk tudni használni. Ebben az esetben nem generál költséget!
4, Figyeljünk a felhasználandó processzorra és memóriára. Ha nem áll rendelkezésre elegendő, a pod-ok nem fognak elindulni!
Ha mindent jól csináltunk, pár perc múlva már el is készül a helyben használható SQL-ünk.
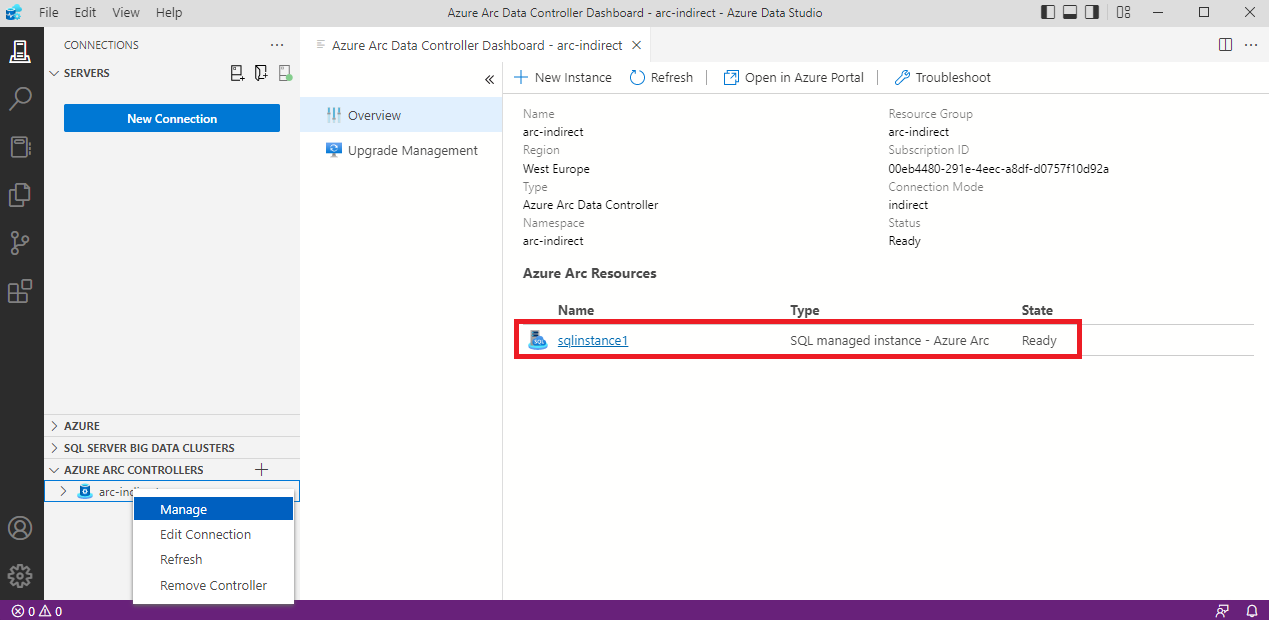
Monitoring
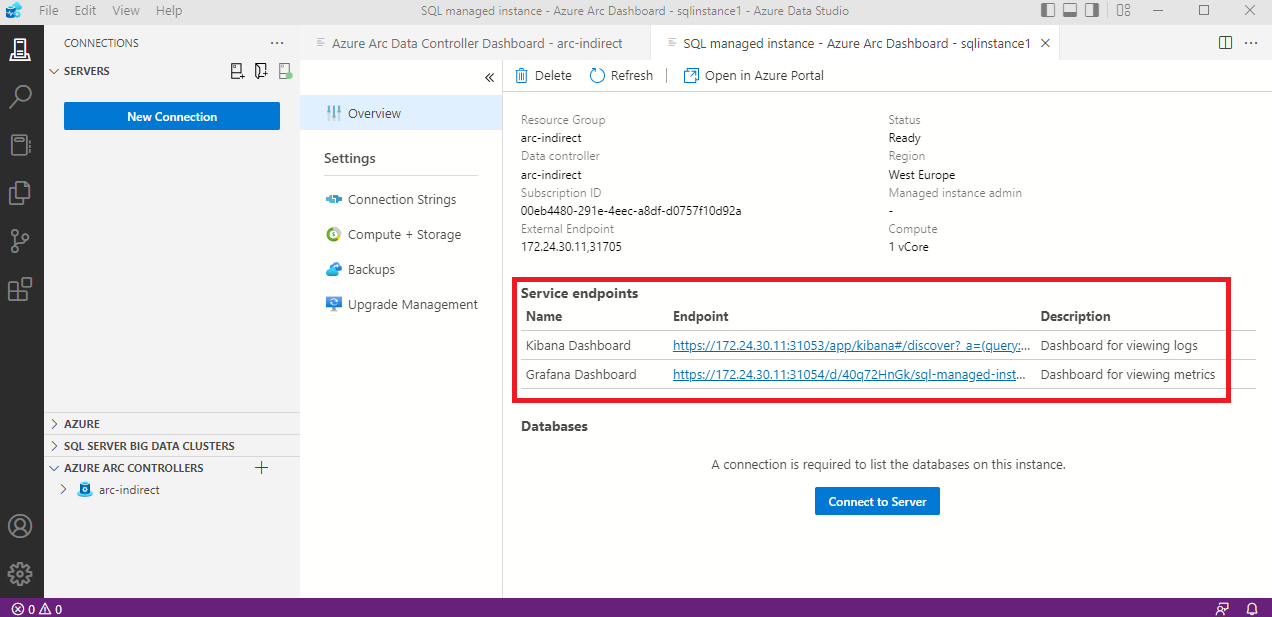
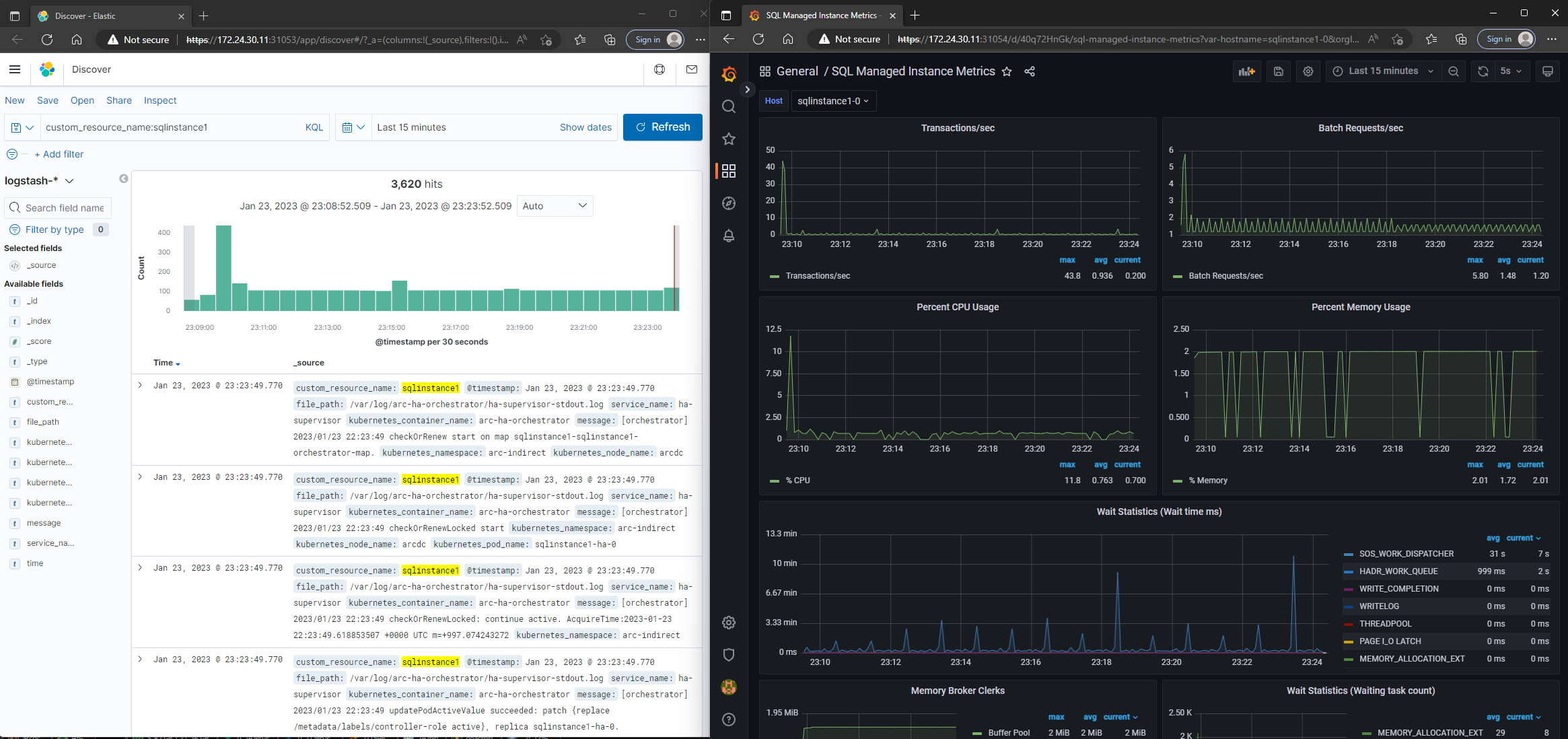
Semmilyen log nem hagyja el a szerverünket, de azért néha szükség van a hibalogok-ra vagy metrica-ra. Szerencsére erre is gondoltak és létrehoztak egy Kibana és egy Grafana Dashboard-ot, hogy nyomonkövethessük a cluster-ünket.
Válasszuk ki az instance-t.
Majd válasszuk ki, hogy mi érdekel minket és nézzük meg mit mutatnak.
A bejelentkezést követően pedig már nézelődhetünk is.
Kapcsolódás
Amennyiben nem jó a tanúsítvány, márpedig IP címeket használunk, vagyis nem lesz jó, így az egyértelmű gombot sajnos nem használhatjuk. Marad a hosszabb út. Másoljuk ki az elérhetőséget és kézzel hozzunk létre egy új kapcsolatot.
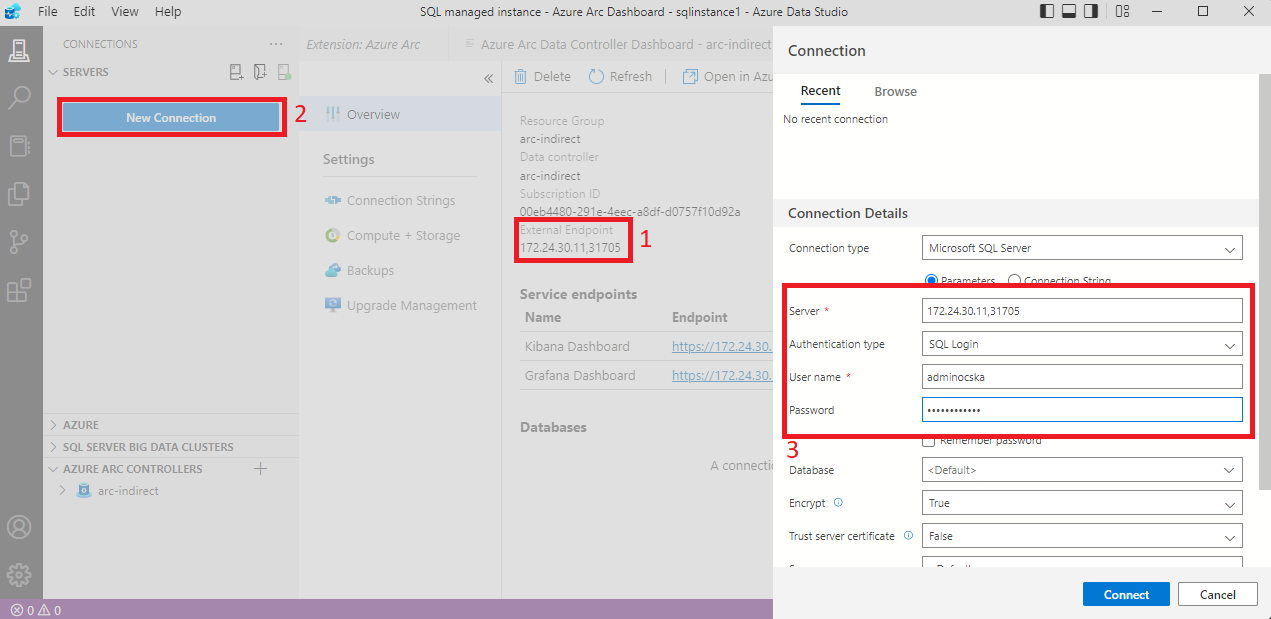
A felugró tanúsítvány hibát el kell fogadnunk, de ezután már el is értük a helyben futtatott Azure Arc-enabled SQL Managed Instance-t.
Usage
Mint már említettem, a használatot időről időre fel kell tölteni. Szerencsére 2 paranccsal meg is oldható ez a feladat és könnyedén automatizálhatjuk is. Részletesebben itt olvashatunk róla.
Provider
Az előfizetésen aktiválni kell az ehhez tartozó provider-t.
1
2
3
az provider register -n Microsoft.AzureArcData --wait
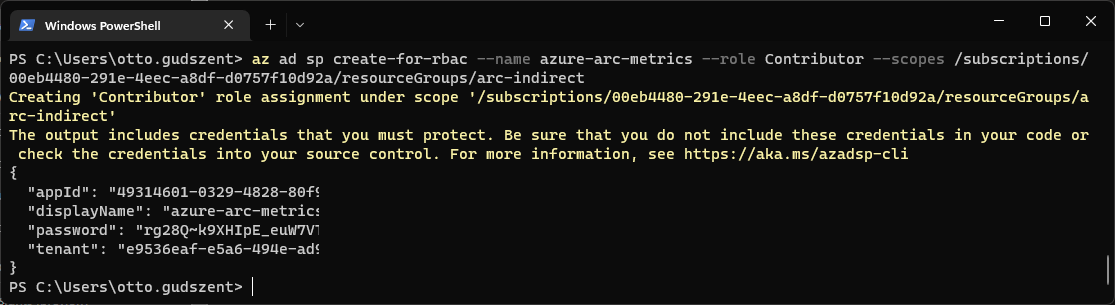
Service Principal
Hozzunk létre egy Service Principal-t, akinek a nevében történik a feltöltés. Itt azt a Resource Group-ot kell megadni, mint elérési út, amit kijelöltünk Data controlle-rnek.
1
2
3
4
5
$rg="/subscriptions/00eb4480-291e-4eec-a8df-d0757f10d92a/resourceGroups/arc-indirect"
az ad sp create-for-rbac --name azure-arc-metrics --role Contributor --scopes $rg
Adjunk még egy jogosultságot az SP-nek.
1
2
3
az role assignment create --assignee <appId> --role "Monitoring Metrics Publisher" --scope $rg
Usage Upload
Legkésőbb 30 naponta fel kell tölteni az adatokat, de javasolt már korábban, hogy legyen idő feldolgozni azokat.
1
2
3
4
5
az arcdata dc export --type usage --path usage.json --force --k8s-namespace <namespace> --use-k8s
az arcdata dc upload --path usage.json